ウェブブラウザはおそらく、最も広く利用されているソフトウェアです。この入門書では、ブラウザの内部のしくみについて説明します。アドレスバーに「google.com」と入力してからブラウザの画面に Google のページが表示されるまでに何が起きているのかがわかります。
対象とするウェブブラウザ
現在利用されている主なブラウザには、Internet Explorer、Firefox、Safari、Chrome、Opera の 5 つがあります。ここでは、オープンソース ブラウザの Firefox、Chrome、Safari(一部オープンソース)を例として取り上げます。StatCounter 社のブラウザに関する調査(リンク先は英語)によると、2011 年 8 月現在、Firefox、Safari、Chrome の利用シェアは合計で 60% 近くに上ります。したがって、現在、オープンソース ブラウザはブラウザ市場で重要な一角を占めていると言えます。
ブラウザの主な機能
ブラウザの主な機能はユーザーの選択したウェブ リソースをサーバーに要求してブラウザ ウィンドウに表示することにより、ユーザーに提示することです。通常、リソースは HTML ドキュメントですが、PDF や画像など、他のタイプのリソースもあります。リソースの場所は URI(Uniform Resource Identifier)を使用してユーザーが指定します。
ブラウザによる HTML ファイルの解釈方法と表示方法は HTML と CSS の仕様で規定されています。これらの仕様はウェブに関する標準化団体「W3C(World Wide Web Consortium)」が管理しています。
ブラウザは長い間、仕様の一部にしか従っておらず、独自の拡張機能が開発されていました。そのため、ウェブ制作者は互換性の問題に頭を悩ませてきました。最近は、ほとんどのブラウザがおおむね仕様に従っています。
ブラウザのユーザー インターフェース(UI)は互いにかなり共通しています。共通のユーザー インターフェース要素には次のようなものがあります。
- URI を入力するためのアドレスバー
- [戻る] ボタンと [進む] ボタン
- ブックマーク機能
- 現在のドキュメントを更新するための [更新] ボタン、読み込みを中止するための [中止] ボタン
- ホーム ページに移動するための [ホーム] ボタン
不思議なことに、ブラウザのユーザー インターフェースは正式な仕様では規定されていません。長年の経験から優れた実践手法が形成され、互いに真似し合うことによって生まれたものです。HTML5 仕様ではブラウザに必須の UI 要素は定義されていませんが、一般的な要素がいくつか挙げられています。たとえば、アドレスバー、ステータスバー、ツールバーなどです。Firefox のダウンロード マネージャなど、特定のブラウザに固有の機能ももちろんあります。
ブラウザの上位構造
ブラウザの主な構成要素は次のとおりです(1.1)。
- ユーザー インターフェース - アドレスバー、戻る/進むボタン、ブックマーク メニューなどがあります。ブラウザ画面のうち、要求したページが表示されるメイン ウィンドウを除くすべての部分です。
- ブラウザ エンジン - UI とレンダリング エンジンの間の処理を整理します。
- レンダリング エンジン - 要求されたコンテンツの表示を担当します。たとえば、要求されたコンテンツが HTML の場合は、HTML と CSS を解析し、解析されたコンテンツを画面に表示します。
- ネットワーキング - HTTP リクエストなどのネットワークの呼び出しに使用されます。プラットフォームに依存しないインターフェースと、プラットフォームごとの下部の実装を備えています。
- UI バックエンド - コンボ ボックスやウィンドウなどの基本的なウィジェットの描画に使用されます。プラットフォームに依存しない汎用的なインターフェースを公開し、その下ではオペレーティング システムのユーザー インターフェース メソッドを使用しています。
- JavaScript インタープリタ - JavaScript コードの解析と実行に使用されます。
- データ ストレージ - 永続的なレイヤです。ブラウザでは Cookie などさまざまなデータをハード ディスクに保存する必要があります。新しい HTML 仕様(HTML5)では、ブラウザ内の完全で軽量なデータベースである「ウェブ データベース」が定義されています。
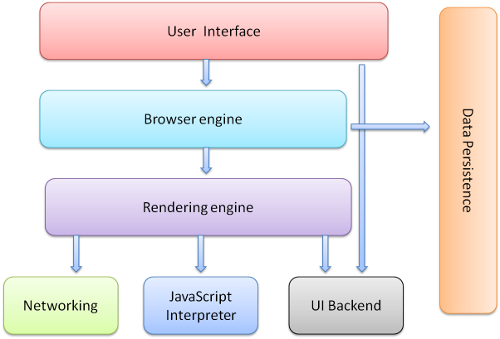
ほとんどのブラウザとは異なり、Chrome ではレンダリング エンジンの複数のインスタンス(各タブに 1 つずつ)が保持される点に注意してください。各タブは別々のプロセスとなります。
レンダリング エンジンの仕事は「レンダリング」、つまり、要求されたコンテンツをブラウザの画面に表示することです。
デフォルトでは、レンダリング エンジンは HTML ドキュメント、XML ドキュメント、画像を表示できます。プラグイン(またはブラウザの拡張機能)を通じて他の種類のファイルも表示できます。たとえば、PDF ビューアを使用して PDF を表示する場合などです。ただし、この章では、「CSS を使って書式設定された HTML と画像を表示する」という主な使い方を取り上げます。
レンダリング エンジン
参考ブラウザの Firefox、Chrome、Safari は 2 つのレンダリング エンジン上に構築されています。Firefox では Mozilla 用の独自のレンダリング エンジンである Gecko を使用しています。Safari と Chrome では Webkit を使用しています。
Webkit はオープンソースのレンダリング エンジンです。Linux プラットフォーム用のエンジンとして始まり、Apple が Mac に対応させるために改良したほか、Windows にも移植されています。詳しくは webkit.org(英語)をご覧ください。
メイン フロー
レンダリング エンジンはまず、要求したドキュメントのコンテンツをネットワーキング レイヤから取得します。この処理は 8 キロバイト単位で行われます。
レンダリング エンジンのその後の基本的なフローは次のとおりです。

レンダリング エンジンは HTML ドキュメントの解析を開始し、タグを「コンテンツ ツリー」というツリー内の DOM ノードに変換します。外部の CSS ファイルと style 要素内のスタイル データを解析します。スタイル情報と HTML 内の視覚的な指示を組み合わせて、「レンダー ツリー」という別のツリーが作成されます。
レンダー ツリーには色や寸法などの視覚的な属性を持つ矩形が含まれています。矩形は画面に表示される正しい順序で並んでいます。
レンダー ツリーが構築されると、「レイアウト」処理に進みます。つまり、画面に表示される正確な座標が各ノードに割り当てられます。次の段階は「描画」です。レンダー ツリーが走査され、UI バックエンド レイヤを使用して各ノードが描画されます。
これは段階的な処理である点を理解しておくことが大切です。ユーザーに快適に操作してもらえるよう、レンダリング エンジンはできるだけ早くコンテンツを画面に表示しようとします。すべての HTML が解析されるのを待ってから、レンダー ツリーの構築とレイアウトを開始するわけではありません。コンテンツの一部が解析され、表示される間に、ネットワークから残りのコンテンツが届いて処理が続けられます。
メイン フローの例
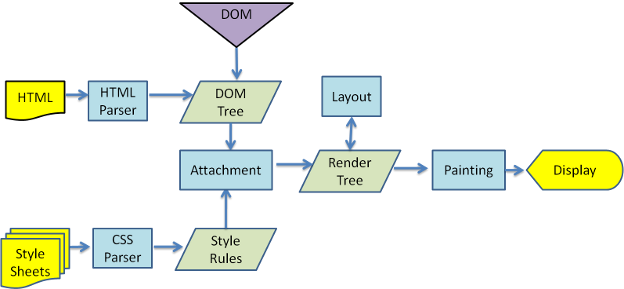
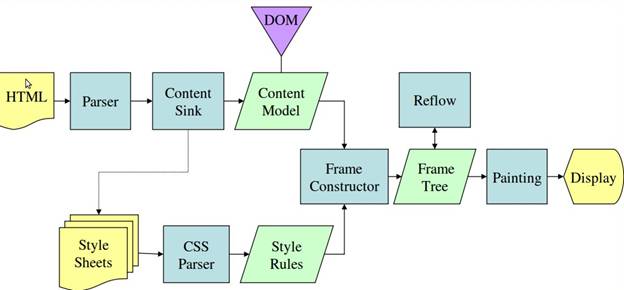
図 3 と図 4 から、Webkit と Gecko では多少異なる用語が使われているのがわかりますが、フローは基本的に同じです。
Gecko では視覚的な書式が設定された要素のツリーを「フレーム ツリー」と呼んでいます。各要素が 1 つのフレームとなります。Webkit では「レンダー ツリー」という用語が使われており、レンダー ツリーは「レンダー オブジェクト」で構成されています。Webkit では要素を配置することを「レイアウト」といいますが、Gecko では「リフロー」と呼んでいます。「関連付け(Attachment)」は、DOM ノードと視覚情報を結び付けてレンダー ツリーを作成することを指す Webkit の用語です。用語の定義以外の違いとして、Gecko には HTML と DOM ツリーの間に追加のレイヤがあります。「コンテンツ シンク」と呼ばれるもので、DOM 要素を作成するためのファクトリです。それでは、フローのそれぞれの部分について説明しましょう。
解析 - 概要
解析はレンダリング エンジンの中で非常に重要な処理なので、少し詳しく見てみましょう。まずは、解析の簡単な説明から始めます。
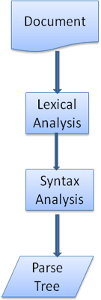
ドキュメントの解析とは、ドキュメントを意味のある構造(コード内で解釈し、使用できる形式)に変換することです。解析結果は通常、ドキュメントの構造を表すノードのツリーになります。これを「解析ツリー」または「構文ツリー」といいます。
例 -「2 + 3 - 1」という式を解析すると、次のようなツリーが返されます。

文法
解析はそのドキュメントが従っている構文ルール(ドキュメントの記述に使われた言語やフォーマットなど)に基づいて行われます。フォーマットを解析するには、そのフォーマットに語彙と構文ルールからなる決定論的な文法がなければなりません。これを「文脈自由文法」といいます。人間の言語はそれに当てはまらないため、従来の解析手法では解析できないのです。
パーサーとレキサーの連携
解析は「字句解析」と「構文解析」の 2 つのサブプロセスに分けることができます。
字句解析は、入力をトークンに分割する処理です。トークンは言語の語彙(有効な構成要素の集まり)に相当します。人間の言語では、その言語の辞書に登場するすべての単語が語彙を構成しています。
構文解析は、言語の構文ルールを適用することです。
通常、パーサーでは処理を 2 つの構成要素に分けて行います。入力を有効なトークンに分割する「レキサー」(または「トークナイザー」)と、言語の構文ルールに従ってドキュメントの構造を分析し、解析ツリーを構築する「パーサー」です。レキサーには空白文字や改行などの関係ない文字を除外する機能があります。
解析は反復的な処理です。パーサーは通常、レキサーに新しいトークンを要求し、トークンを構文ルールのいずれかと一致させようとします。ルールが一致した場合、そのトークンに対応するノードが解析ツリーに追加され、パーサーは別のトークンを要求します。
ルールが一致しない場合はトークンを内部的に格納しておき、内部に格納したすべてのトークンが一致するルールが見つかるまで、トークンを要求し続けます。ルールが見つからない場合、パーサーは例外を生成します。ドキュメントが有効ではなく、構文エラーが含まれていたことになります。
変換
多くの場合、最終的に生成されるのは解析ツリーではありません。解析は変換(入力されたドキュメントを別の形式に変換すること)にもよく使用されます。例としてコンパイルが挙げられます。ソース コードをマシン コードにコンパイルするコンパイラでは、最初にソース コードを解析して解析ツリーを作成し、次に解析ツリーをマシン コードのドキュメントに変換します。

解析の例
図 5 では数式から解析ツリーを作成しました。簡単な数学的言語を定義して、解析処理を見てみましょう。
語彙: この言語では、整数とプラス記号、マイナス記号を使用できます。
構文:
- この言語の構文の構成要素は、式、項、演算です。
- この言語には式をいくつでも含めることができます。
- 「項」の後に「演算」が続き、さらに別の「項」が続いたものを「式」と定義します。
- 演算はプラスのトークンまたはマイナスのトークンです。
- 項は整数のトークンか式です。
それでは、「2 + 3 - 1」という入力を分析してみましょう。
ルールに一致する最初の文字列は「2」で、ルール 5 によると「項」になります。2 番目に一致するのは「2 + 3」です。項の後に演算が続き、さらに別の項が続いているので、ルール 3 に一致します。次の一致は入力の最後まで進むとヒットし、「2 + 3 - 1」が式になります。既に「2+3」が項だとわかっているので、項の後に演算が続き、さらに別の項が続いていることになります。たとえば、「2 + +」はどのルールにも一致しないため、無効な入力となります。
語彙と構文の正式な定義
通常、語彙は正規表現(リンク先は英語)で表します。
たとえば、サンプルの言語は次のように定義されます。
INTEGER :0|[1-9][0-9]* PLUS : + MINUS: -
ご覧のとおり、整数は正規表現で定義されています。
構文は通常、「BNF」という形式で定義します。サンプルの言語は次のように定義されます。
expression := term operation term operation := PLUS | MINUS term := INTEGER | expression
先ほど、文法が文脈自由文法である場合、その言語は通常のパーサーで解析できると説明しました。簡単に定義すると、文脈自由文法とは BNF で完全に表現できる文法のことです。正しい定義については、文脈自由文法に関する Wikipedia の記事をご覧ください。
パーサーの種類
パーサーには、「トップダウン パーサー」と「ボトムアップ パーサー」という 2 つの基本的な種類があります。簡単に説明すると、トップダウン パーサーは構文の上位構造を調べて、いずれかの構文ルールと一致させようとします。ボトムアップ パーサーはまず入力を調べて、段階的に構文ルールに変換していきます。下位のルールから開始し、上位のルールが一致するまで続けます。
2 種類のパーサーでサンプルがどのように解析されるか見てみましょう。
トップダウンパーサーは上位のルールから始めて、「2 + 3」を式として特定します。次に、「2 + 3 - 1」を式として特定します(式を特定する処理は他のルールのマッチングに発展しますが、出発点は上位のルールです)。
ボトムアップ パーサーはルールに一致するまで入力をスキャンし、一致した入力をルールで置き換えます。この手順が入力の最後まで続きます。部分的に一致した式はパーサーのスタックに格納されます。
| スタック | 入力 |
|---|---|
| 2 + 3 - 1 | |
| 項 | + 3 - 1 |
| 項、演算 | 3 - 1 |
| 式 | - 1 |
| 式、演算 | 1 |
| 式 |
このタイプのボトムアップ パーサーは「シフト - 還元パーサー(shift-reduce parser)」と呼ばれます。入力が右側にシフトされ(ポインタが最初は入力の先頭を指し、右側に移動していくイメージ)、段階的に構文ルールに還元されるためです。
パーサーの自動生成
独自のパーサーを生成できるツールがあり、「パーサー ジェネレータ」と呼ばれています。言語の文法(語彙と構文ルール)を指定すると、作業用のパーサーが生成されます。パーサーを作成するには解析に関する深い知識が必要となり、手作業で最適なパーサーを作成するのは簡単ではないため、パーサー ジェネレータは大変便利です。
Webkit では 2 つの有名なパーサー ジェネレータを使用しています。レキサー作成用の Flex とパーサー作成用の Bison です(リンク先は英語)。「Lex」と「Yacc」という名前でご存知かもしれません。Flex の入力は、トークンの正規表現での定義を含むファイルです。Bison の入力は、BNF 形式で記述した言語の構文ルールです。
HTML パーサー
HTML パーサーの役割は、HTML マークアップを解析して解析ツリーを作成することです。
HTML の文法の定義
HTML ドキュメントの語彙と構文は、標準化団体 W3C が策定する仕様で定義されています。現在のバージョンは HTML4 で、HTML5 に関する作業が進んでいます。
文脈自由文法ではない
解析の概要で述べたように、文法の構文は BNF などの形式を使って正式に定義できます。
しかし、これまでのパーサーに関する説明がすべて HTML に当てはまるわけではありません(CSS や JavaScript の解析に利用される部分もあります)。HTML は、パーサーが必要とする文脈自由文法では簡単に定義できません。
HTML を定義するための正式な形式として「DTD(Document Type Definition)」がありますが、DTD は文脈自由文法ではありません。
このことは一見、不思議に思えるかもしれません。HTML はむしろ XML に近く、さまざまな XML パーサーも普及しています。HTML を XML に対応させた XHTML という言語もあります。どこに大きな違いがあるのでしょうか。
違うのは、HTML がより「寛大」な姿勢をとっていることです。追加した特定のタグをうっかり削除したり、開始タグや終了タグを忘れたりしても許容されることがあります。XML の厳密で要求の多い構文とは反対に、全体的に HTML は「緩やかな」構文です。
これはわずかな違いのようでも、話は大きく変わってきます。HTML が広く普及した主な理由はこの寛容性にありますが(誤りが見逃されるため、ウェブ制作者にとっては楽になります)、その一方で、正式な文法を記述するのが難しくなっています。つまり、HTML の文法は文脈自由文法ではないため、従来のパーサーや XML パーサーでは HTML を簡単に解析できないのです。
HTML DTD
HTML の定義は DTD 形式です。この形式は SGML ファミリーの言語を定義するのに使用されます。許可されるすべての要素とその属性や階層の定義が含まれています。前述のように、HTML DTD は文脈自由文法ではありません。
DTD にはいくつかのバリエーションがあります。厳密(strict)モードは仕様にのみ従っていますが、他のモードでは過去のブラウザで使用されたマークアップに対応しています。古いコンテンツとの下位互換性を維持するのが目的です。現在の厳密な DTD は www.w3.org/TR/html4/strict.dtd にあります。
DOM
生成される「解析ツリー」は DOM 要素と属性のノードのツリーです。DOM は「Document Object Model」の略で、HTML ドキュメントや、HTML 要素と JavaScript などの外部世界とのインターフェースをオブジェクトで表現したものです。
ツリーのルートは「Document」オブジェクトです。
DOM とマークアップはほぼ 1 対 1 の関係になっています。たとえば、次のようなマークアップがある場合、
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
次のような DOM ツリーに変換されます。
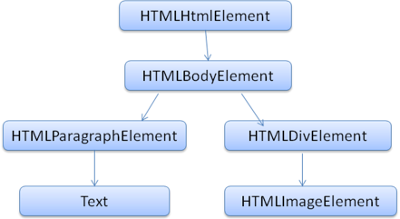
HTML と同様に、DOM も標準化団体 W3C が策定しています。www.w3.org/DOM/DOMTR をご覧ください。これはドキュメントの操作に関する全般的な仕様です。特定のモジュールで HTML に固有の要素が説明されており、HTML の定義は www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html(英語)にあります。
「ツリーに DOM ノードが含まれる」というのは、「DOM インターフェースのいずれかを実装する要素でツリーが構築されている」という意味です。ブラウザが使用する具体的な実装には、ブラウザで内部的に使用される他の属性が含まれています。
解析アルゴリズム
前のセクションで説明したように、HTML は通常のトップダウン パーサーやボトムアップ パーサーでは解析できません。
その理由は次のとおりです。
- 言語の寛容な性質。
- 無効な HTML のよく知られたケースに対応するため、ブラウザでこれまでエラーが許容されてきたこと。
- 解析処理が「再入可能(リエントラント)」であること。通常は解析中にソースが変更されることはありませんが、HTML では、「
document.write」を含むスクリプト タグによってさらにトークンが追加される場合があるため、実際には解析処理中に入力が変更されます。
通常の解析手法を使用できないため、ブラウザでは HTML 解析用のカスタム パーサーを作成しています。
HTML5 仕様(英語)では、解析アリゴリズムが詳しく説明されています。アルゴリズムは「トークン化」と「ツリー構築」の 2 段階で構成されています。
トークン化は字句解析であり、入力を解析してトークンに分割します。HTML トークンには、開始タグ、終了タグ、属性名、属性値などがあります。
トークナイザーはトークンを識別し、ツリー コンストラクタに渡すと、次のトークンを識別するために次の文字を処理します。これを入力の最後まで続けます。

トークン化アルゴリズム
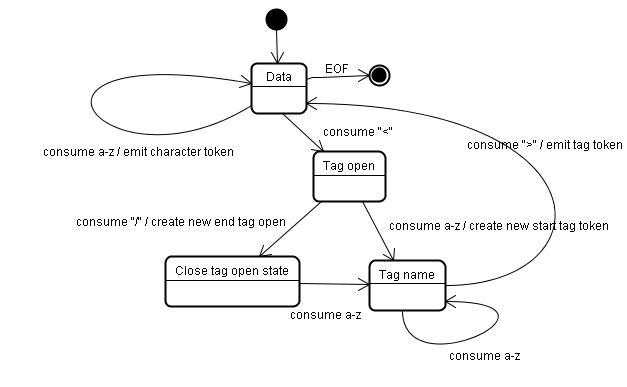
このアルゴリズムの出力は HTML トークンです。アルゴリズムはステート マシン(状態マシン)として表現されます。各状態では入力ストリームの 1 つまたは複数の文字を処理し、その文字に従って次の状態が更新されます。この判断は、現在のトークン化の状態とツリー構築の状態に影響されます。つまり、同じ文字を処理しても、現在の状態に応じて、次の状態は異なる結果になります。アルゴリズムは複雑なため詳細には説明できませんが、原理がわかりやすくなるように簡単な例を見てみましょう。
基本的な例: 次のような HTML をトークン化します。
<html>
<body>
Hello world
</body>
</html>
最初の状態は「データ状態」です。< 文字に遭遇すると、状態は「タグ開始状態」に変わります。a-z 文字を読み込むと「開始タグ トークン」の作成が始まり、状態は「タグ名状態」に変わります。> 文字が読み込まれるまでこの状態に留まります。それぞれの文字が新しいトークン名に追加されていきます。この例で作成されるのは html トークンです。
> タグに達すると、現在のトークンが出力され、状態は再び「データ状態」に変わります。<body> タグも同じ手順で処理されます。ここまでで html タグと body タグが出力されました。再び「データ状態」に戻ります。Hello world の H 文字を読み込むと、文字トークンの作成と出力が始まり、</body> の < に達するまで続きます。Hello world のそれぞれの文字に対応する文字トークンが出力されます。
再び「タグ開始状態」に戻ります。次の入力 / を読み込むと「終了タグトークン」の作成が始まり、「タグ名状態」に移ります。再び、> に達するまでこの状態に留まります。新しいタグ トークンが出力されると「データ状態」に戻ります。</html> の入力も同様に処理されます。
ツリー構築アリゴリズム
パーサーの作成時に Document オブジェクトが作成されます。ツリー構築段階で、ルートに Document を持つ DOM ツリーが変更され、要素が追加されていきます。トークナイザーで出力された各ノードがツリー コンストラクタによって処理されます。仕様では、トークンごとに関連する DOM 要素が定義されており、そのトークンに対応する DOM 要素が作成されます。要素は DOM ツリーに追加されるほか、オープンな要素のスタックに追加されることもあります。このスタックは、入れ子のタグの不一致や閉じていないタグの修正に使用されます。このアルゴリズムもステート マシンに相当し、状態は「挿入モード」と呼ばれます。
サンプル入力のツリー構築処理を見てみましょう。
<html>
<body>
Hello world
</body>
</html>
ツリー構築段階への入力はトークン化段階からの一連のトークンです。最初のモードは「initial」モードです。html トークンを受け取ると「before html」モードに移り、そのモードでトークンの再処理が行われます。HTMLHtmlElement 要素が作成され、ルートの Document オブジェクトに追加されます。
モードは「before head」に変わります。次に body トークンを受け取ります。トークン名は「head」ではありませんが、暗黙的に HTMLHeadElement が作成され、ツリーに追加されます。
ここで「in head」モードに移り、次に「after head」モードに移ります。body トークンが再処理され、HTMLBodyElement が作成および挿入されると、モードは「in body」に移ります。
次に「Hello world」文字列の文字トークンを受け取ります。最初の文字で「Text」ノードの作成と挿入が行われ、他の文字がそのノードに追加されていきます。
body end トークンを受け取ると、「after body」モードに移ります。html end トークンを受け取ると、「after after body」モードに移ります。end of file トークンを受け取ると解析が終了します。

解析終了時の動作
この段階で、ブラウザはドキュメントを「インタラクティブ」とマークし、「遅延(deferred)」モードのスクリプト(ドキュメントの解析後に実行すべきスクリプト)の解析を開始します。その後でドキュメントの状態は「完了」に設定され、「読み込み」イベントが開始されます。
トークン化とツリー構築の詳細なアルゴリズムについては、HTML5 仕様(英語)をご覧ください。
ブラウザ エラーの許容
HTML ページで「無効な構文」エラーが発生することはありません。ブラウザは無効なコンテンツを修正して、処理を続けます。
たとえば、次のような HTML を見てみましょう。
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
ルールに違反した部分がいくつもありますが(「mytag」が標準のタグではない、「p」要素と「div」要素の入れ子に誤りがあるなど)、ブラウザでは適切に表示され、エラーは発生しません。パーサーのコードが HTML 作成者の間違いを修正してくれるのです。
エラー処理はどのブラウザでも同じように行われていますが、驚くことに、現在の HTML 仕様では規定されていません。ブックマーク機能や戻る/進むボタンのように、長年にわたりブラウザで発展してきたに過ぎません。無効な HTML の構成には多数のサイトで繰り返される、よく知られたものがありますが、ブラウザは他のブラウザと同じ方法で修正しようとします。
HTML5 仕様では、エラー処理に関するいくつかの要件を定義しています。Webkit では、HTML パーサー クラスの冒頭のコメントで、その要件をわかりやすくまとめています。
パーサーはトークン化された入力を解析してドキュメント ツリーを構築します。ドキュメントの形式が正しい場合、解析は容易です。
残念ながら、形式が正しくない HTML ドキュメントを多数処理する必要があるため、パーサーはエラーに対して寛容でなければなりません。
少なくとも次のようなエラー状態を考慮する必要があります。
- 追加されたタグは、外側のタグに入れることが明示的に禁止されている場合。この場合は、その要素を禁止しているタグまでのすべてのタグを閉じて、その後に要素を追加します。
- パーサーでは要素を直接追加することはできません。ドキュメントの作成者が間にタグを挿入し忘れたか、間のタグが省略可能である場合も考えられます。このケースに該当するタグは、HTML、HEAD、BODY、TBODY、TR、TD、LI などです。
- ブロック要素をインライン要素の中に追加したい場合は、次の上位のブロック要素に到達するまでに、すべてのインライン要素を閉じてください。
- この対応が役立たない場合は、要素を追加できる、またはタグを無視できるところまで要素を閉じます。
それでは、Webkit のエラー許容の例を見てみましょう。
<br> の代わりの </br>
サイトによっては、<br> の代わりに </br> を使用している場合があります。IE や Firefox との互換性を保つため、Webkit では <br> のように扱います。
コードは次のとおりです。
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
注 - エラー処理は内部的に行われ、ユーザーには表示されません。
迷子のテーブル
迷子のテーブルとは、別のテーブル コンテンツの中にあるのに、テーブルのセルに入っていないテーブルのことです。
次の例の場合、
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
Webkit は階層を 2 つの同等のテーブルに変更します。
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
コードは次のとおりです。
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
Webkit は現在の要素のコンテンツに対してスタックを使用しています。外側のテーブルのスタックから内側のテーブルを取り出すことで、2 つのテーブルが同等になります。
入れ子のフォーム要素
フォームが別のフォームの中にある場合、2 番目のフォームは無視されます。
コードは次のとおりです。
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
深すぎるタグ階層
コメントで次のように説明されています。
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
配置に誤りのある html または body 終了タグ
やはり、コメントで次のように説明されています。
破損した HTML への対応です。Webkit が body タグを閉じることはありません。ドキュメントがまだ終わらないのに閉じている不完全なウェブページがあるためです。end() の呼び出しを使って閉じることにしましょう。
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
ウェブ制作者は、Webkit のエラー許容のサンプル コードとして挙げられないように、正しい形式の HTML を記述するようにしましょう。
CSS の解析
概要の章にある解析の概念を思い出してみましょう。HTML とは異なり、CSS は文脈自由文法なので、概要で述べた種類のパーサーを使って解析することができます。CSS 仕様(英語)では、CSS の語彙文法と構文文法を定義しています。
いくつか例を見てみましょう。
語彙文法(語彙)はトークンごとに正規表現で定義します。
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
「ident」は「identifier(識別子)」の略で、クラス名などです。「name」は要素 ID です(「#」で参照されます)。
構文文法は BNF 形式で記述します。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
説明: ルールセットは次のような構造になっています。
div.error , a.error {
color:red;
font-weight:bold;
}
「div.error」と「a.error」はセレクタです。波かっこで囲まれた部分には、このルールセットで適用されるルールが入ります。この構造は正式には次のように定義されています。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
つまり、ルールセットはセレクタであり、カンマとスペースで区切って複数のセレクタを指定することもできます(「S」は空白を表します)。ルールセットには波かっこが含まれており、波かっこの中に宣言が入ります。セミコロンで区切って複数の宣言を指定することもできます。「宣言」と「セレクタ」はその後の BNF 定義で定義されます。
Webkit の CSS パーサー
Webkit では Flex と Bison パーサー ジェネレータを使用して、CSS 文法ファイルからパーサーを自動的に作成します。パーサーの概要で説明したとおり、Bison ではボトムアップ型のシフト - 還元パーサーが作成されます。Firefox では手動で記述されたトップダウン パーサーを使用しています。どちらの場合も、各 CSS ファイルを解析して StyleSheet オブジェクトを生成し、各オブジェクトに CSS ルールを格納します。CSS ルール オブジェクトには、セレクタ オブジェクト、宣言オブジェクト、CSS 文法に対応するその他のオブジェクトがあります。
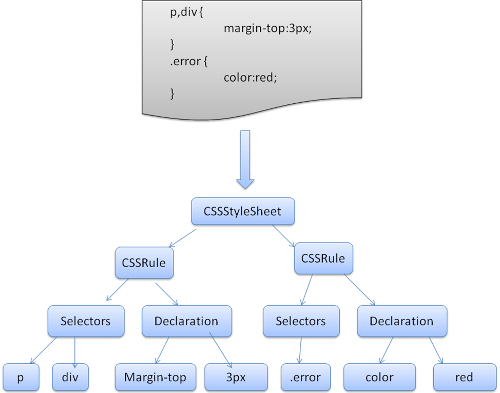
スクリプトとスタイル シートの処理順序
スクリプト
ウェブのモデルは同期的です。制作者は、パーサーが <script> タグに達するとすぐにスクリプトが解析、実行されると想定しています。ドキュメントの解析はスクリプトが実行されるまで中断されます。スクリプトが外部にある場合は、最初にネットワークからリソースを取得する必要があります。この処理も同期的に行われるため、リソースを取得するまで解析は中断されます。これは長年使われてきたモデルで、HTML 4 および 5 仕様でも指定されています。スクリプトは「遅延(defer)」としてマークすることができます。その場合、ドキュメントの解析は中断されず、解析後にスクリプトが実行されます。HTML5 ではスクリプトを「非同期(async)」としてマークするオプションが追加されました。その場合、スクリプトは別のスレッドで解析、実行されます。
投機的な解析
Webkit と Firefox のいずれもこの最適化を行っています。スクリプトの実行中に別のスレッドでドキュメントの残りを解析し、ネットワークから読み込む必要のある他のリソースを探して、読み込みます。このようにリソースの読み込みを並列接続上で行うため、全体的な速度が向上します。なお、投機的なパーサーでは DOM ツリーは変更せず、メインのパーサーに委ねています。外部にあるスクリプト、スタイル シート、画像などの外部リソースへの参照のみを解析します。
スタイル シート
一方、スタイル シートは異なるモデルです。理論的には、スタイル シートは DOM ツリーを変更しないため、スタイル シートの読み込みを待ってドキュメントの解析を中断する理由はないように思われます。しかし、ドキュメントの解析段階でスクリプトがスタイル情報を要求するという問題があります。スタイルの読み込みと解析がまだ済んでいない場合、スクリプトは誤った回答を受け取ることになり、さまざまな問題を引き起こす可能性があります。これは特殊なケースのように見えますが、実際にはよく起きています。Firefox では、読み込みや解析が途中のスタイル シートがある場合、すべてのスクリプトをブロックしています。Webkit では、まだ読み込まれていないスタイル シートの影響を受けそうな特定のスタイル プロパティにスクリプトがアクセスしようとした場合にのみ、スクリプトをブロックします。
レンダー ツリーの構築
DOM ツリーを構築する間に、ブラウザは「レンダー ツリー」という別のツリーも構築します。このツリーは、視覚的な要素を表示順に並べたツリーであり、ドキュメントの視覚的な表現です。レンダー ツリーの目的は、コンテンツを正しい順序で描画できるようにすることです。
Firefox ではレンダー ツリー内の要素を「フレーム」と呼んでいます。Webkit では「レンダラー」または「レンダー オブジェクト」といいます。
レンダラーは自身とその子のレイアウト方法と描画方法を認識しています。
Webkit のレンダラーの基本クラスである RenderObject クラスは次のように定義されています。
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
各レンダラーは、通常はノードの CSS ボックス(CSS2 仕様の説明を参照)に相当する矩形の領域を表しており、幅、高さ、位置などの幾何学的情報が含まれています。
ボックスの種類は、そのノードに関連する「display」スタイル属性に影響されます(スタイルの計算をご覧ください)。次の Webkit のコードは、DOM ノードに対してどの種類のレンダラーを作成するかを display 属性に従って決定するコードです。
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
要素の種類も考慮されます。たとえば、フォーム コントロールやテーブルには特別なフレームがあります。
Webkit では、要素で特別なレンダラーの作成が必要な場合、
createRendererメソッドがオーバーライドされます。レンダラーは、非幾何学的情報を含むスタイル オブジェクトを指しています。
レンダー ツリーと DOM ツリーの関係
レンダラーは DOM 要素に対応していますが、その関係は 1 対 1 ではありません。視覚的でない DOM 要素はレンダー ツリーに挿入されません。その例として「head」要素が挙げられます。display 属性に「none」が指定されている要素もツリーには含まれません(visibility 属性に「hidden」が指定された要素はツリーに含まれます)。
DOM 要素が複数の視覚的オブジェクトに対応している場合があります。通常は、1 つの矩形では記述できない複雑な構造を持つ要素です。たとえば、「select」要素には、表示領域、プルダウン リスト ボックス、ボタンに対応する 3 つのレンダラーがあります。また、1 行では幅が足りないためテキストを複数行に分割する場合は、新しい行が別のレンダラーとして追加されます。
複数のレンダラーのもう 1 つの例として、分割された HTML が挙げられます。CSS 仕様によると、インライン要素にはブロック要素のみ、またはインライン要素のみを含める必要があります。混合したコンテンツの場合は、インライン要素をラップするために匿名のブロック レンダラーが作成されます。
レンダラー オブジェクトによっては、1 つの DOM ノードに対応していても、ツリー内の同じ場所にないものもあります。フロートや絶対的に配置された要素は、フローから外れてツリー内の別の場所に置かれてから、実際のフレームにマッピングされます。それらに対応する場所にはプレースホルダ フレームが配置されます。

ツリー構築のフロー
Firefox では、プレゼンテーションが DOM 更新のリスナーとして登録されます。プレゼンテーションはフレームの作成を FrameConstructor に委譲します。このコンストラクタがスタイルを解決して(スタイルの計算をご覧ください)、フレームを作成します。
Webkit では、スタイルを解決してレンダラーを作成する処理を「関連付け(attachment)」といいます。各 DOM ノードには「attach」メソッドがあります。関連付けは同期的に行われ、DOM ツリーにノードが挿入されると、新しいノードの「attach」メソッドが呼び出されます。
html タグと body タグを処理すると、レンダー ツリーのルートが構築されます。ルートのレンダー オブジェクトは CSS 仕様で「包含ブロック」と呼ばれるものに相当します(他のすべてのブロックを含む最上位のブロックです)。その寸法はビューポート(ブラウザ ウィンドウの表示領域の寸法)です。このルートのオブジェクトは、Firefox では「ViewPortFrame」、Webkit では「RenderView」と呼ばれており、ドキュメントが指しているレンダー オブジェクトです。ツリーの残りの部分は DOM ノードを挿入して構築されます。
処理モデルについては、CSS2 仕様(英語)をご覧ください。
スタイルの計算
レンダー ツリーを構築するには、各レンダー オブジェクトの視覚的プロパティを計算する必要があります。この処理は各要素のスタイル プロパティを計算することで行います。
スタイルには、さまざまなソースのスタイル シート、インラインのスタイル要素、HTML 内の視覚的なプロパティ(「bgcolor」プロパティなど)があります。後者は一致する CSS スタイル プロパティに変換されます。
スタイル シートのソースとしては、ブラウザのデフォルトのスタイル シート、ページ作成者が提供するスタイル シート、ユーザーのスタイル シートがあります。ユーザーのスタイル シートとは、ブラウザのユーザーが用意したスタイル シートのことです(ブラウザでお気に入りのスタイルを定義できます。たとえば、Firefox では、「Firefox プロファイル」フォルダにスタイル シートを配置します)。
スタイルの計算にはいくつかの問題点があります。
- スタイル データは多数のスタイル プロパティを含む非常に大きな構造体なので、メモリの問題が起きる可能性があります。
-
最適化されていない場合、要素ごとにマッチング ルールを探索すると、パフォーマンスの問題が起きる可能性があります。各要素のルール リスト全体を走査して一致を探すのは負担の重いタスクです。セレクタの構造は複雑になることがあります。見込みのありそうなパスでマッチング処理を開始して、無駄だと判明した場合は、別のパスを試さなければなりません。
たとえば、次のような複合的なセレクタがあります。
div div div div{ ... }この場合、3 つの div の子孫である<div>にルールが適用されます。特定の<div>要素にルールが該当するかどうかをチェックするとします。特定のパスを選び、ツリーをさかのぼってチェックします。ノード ツリーをさかのぼって走査しても、2 つの div しか見つからず、ルールが該当しないと判明することもあります。その場合はツリーの別のパスを試さなければなりません。 - 適用するルールには、ルールの階層を定義した非常に複雑なカスケード ルールもあります。
それでは、ブラウザがこれらの問題にどのように対処しているか見てみましょう。
スタイル データの共有
Webkit のノードはスタイル オブジェクト(RenderStyle)を参照しています。条件によっては、複数のノードでこのオブジェクトを共有することができます。ノードが「兄弟」か「いとこ」の関係にあり、要素が次の条件に該当する場合です。
- マウスの状態が同じ(たとえば、一方が「:hover」で、もう一方が「:hover」でない場合は該当しない)。
- いずれの要素にも id がない。
- タグ名が一致する。
- クラス属性が一致する。
- マッピングされた属性のセットが同一である。
- リンクの状態が一致する。
- フォーカスの状態が一致する。
- いずれの要素も属性セレクタの影響を受けていない。「影響を受ける」とは、セレクタ内のどこかに属性セレクタを使用しているセレクタの照合がある場合です。
- 要素にインラインのスタイル属性がない。
- 「兄弟」セレクタがまったく使用されていない。WebCore では、兄弟セレクタに遭遇した場合は単にグローバル スイッチを送出し、表示時のドキュメント全体のスタイル共有を無効にします。これには + セレクタ、「:first-child」や「:last-child」などのセレクタがあります。
Firefox のルール ツリー
Firefox にはスタイル計算を容易にするため、さらに、「ルール ツリー」と「スタイル コンテキスト ツリー」という 2 つのツリーがあります。Webkit にもスタイル オブジェクトがありますが、スタイル コンテキスト ツリーのようなツリーには格納されず、関連するスタイルを指している DOM ノードにのみ格納されます。
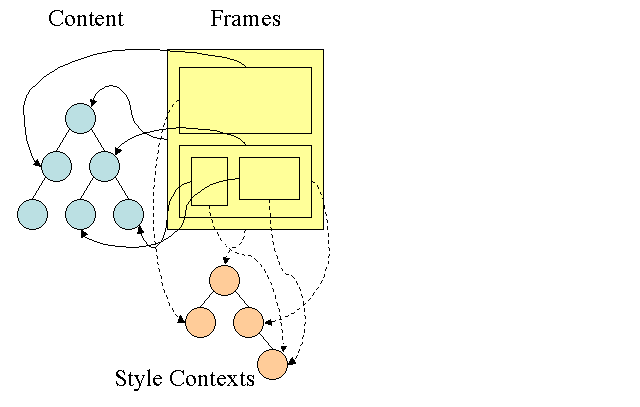
スタイル コンテキストには最終的な値が格納されます。この値の計算では、すべてのマッチング ルールを正しい順序で適用し、論理的な値から具体的な値に変換する操作を行います。たとえば、論理的な値が画面に対する割合である場合、計算後に絶対単位に変換されます。ルール ツリーというアイデアは大変合理的です。ノード間でこれらの値を共有して、計算の繰り返しを避けることができます。スペースの節約にもなります。
一致したルールはすべてツリーに格納されます。パス内の下位のノードの方が優先度が高くなります。ツリーには、見つかったルールの一致に対応するすべてのパスが含まれます。ルールの格納はレイジーに行われます。どのノードでもツリーは当初は計算されていませんが、ノード スタイルを計算する必要が生じると、計算されたパスがツリーに追加されます。
これは、語彙内の単語としてツリー パスを捉えるという考え方です。たとえば、次のようなルール ツリーを既に計算済みだとします。

コンテンツ ツリーの別のノードでルールのマッチングを行う必要があり、一致するルール(正しい順序)として「B - E - I」が見つかったとします。既に「A - B - E - I - L」というパスを計算済みなので、ツリーには既に一致したパスが存在しています。その分、作業を省略できることになります。
それでは、ツリーによって作業が省略されるしくみを見てみましょう。
構造体への分割
スタイル コンテキストは構造体(struct)に分かれています。この構造体には、ボーダーや色など、特定の種類のスタイル情報が格納されます。構造体のすべてのプロパティは「継承型」か「非継承型」です。継承型のプロパティとは、要素で定義されていない場合はその親から継承されるプロパティです。非継承型のプロパティ(「リセット」プロパティともいいます)では、定義されていない場合はデフォルト値が使用されます。
構造体全体(計算済みの最終値を含む)をツリーにキャッシュすることができます。下位のノードで構造体の定義に対応できない場合は、上位のノードにキャッシュされている構造体を使用できます。
ルール ツリーを使用したスタイル コンテキストの計算
特定の要素のスタイル コンテキストを計算する場合は、まず、ルール ツリー内のパスを計算するか、既存のパスを使用します。次に、パスのルールを適用して、新しいスタイル コンテキストの構造体を埋めていきます。パスの下位ノード(優先度が一番高いノード。通常は最も限定的なセレクタ)から始めて、構造体が埋まるまでツリーをさかのぼります。そのルール ノードに構造体の定義がない場合は、構造体を完全に定義し、直接指しているノードが見つかるまでツリーをさかのぼります。ここが最適化されている点で、構造体全体が共有されることになります。これにより最終値の計算が省略され、メモリも節約できます。
部分的な定義が見つかった場合は、構造体が埋まるまでツリーをさかのぼります。
構造体の定義が見つからなかった場合、構造体が「継承型」の場合は、コンテキスト ツリー内の親の構造体を指すことになります。この場合も構造体は共有されます。「リセット型」の構造体の場合は、デフォルト値が使用されます。
最も限定的なノードで値が追加される場合は、その値を実際の値に変換するために余分な計算が必要になります。計算結果は、子が使用できるようにツリー ノードにキャッシュされます。
ある要素に同じツリー ノードを指している兄弟がある場合は、スタイル コンテキスト全体を互いに共有できます。
それでは、例を見てみましょう。次のような HTML があるとします。
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
ルールは次のとおりです。
div {margin:5px;color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
わかりやすくするため、color 構造体と margin 構造体の 2 つの構造体のみを埋める必要があるとします。color 構造体には 1 つのメンバー(color)しかありません。margin 構造体には 4 つの辺があります。
生成されるルール ツリーは次のとおりです(ノードの表記は「ノード名 : 該当するルール番号」です)。

コンテキスト ツリーは次のようになります(ノード名 : 該当するルール ノード)。

HTML を解析し、2 番目の <div> タグに到達したとします。このノードのスタイル コンテキストを作成し、そのスタイル構造体を埋める必要があります。
ルールのマッチングを行うと、<div> に一致するルールとして 1、2、6 が見つかります。つまり、ツリーには既に、この要素で使用できる既存のパスが存在するため、ルール 6(ルール ツリーのノード F)に対応する 1 つのノードをツリーに追加するだけで済みます。
スタイル コンテキストを作成してコンテキスト ツリーに格納します。新しいスタイル コンテキストはルール ツリーのノード F を指しています。
ここで、スタイル構造体を埋める必要があります。まず、margin 構造体から始めます。最後のルール ノード(F)は margin 構造体に対応しないため、以前のノードの挿入で計算されたキャッシュ済みの構造体が見つかるまでツリーをさかのぼり、見つかった構造体を使用できます。margin ルールが指定された最上位のノードであるノード B で見つかります。
color 構造体の定義は既にあるため、キャッシュ済み構造体は使用できません。color の属性は 1 つなので、他の属性を埋めるためにツリーをさかのぼる必要はありません。最終値(文字列を RGB に変換するなど)を計算し、計算後の構造体をこのノードにキャッシュします。
2 番目の <span> 要素の処理はこれよりも簡単です。ルールのマッチングを行うと、前の span と同様にルール G を指していることがわかります。同じノードを指している兄弟があるため、スタイル コンテキスト全体を共有し、前の span のコンテキストを指すだけで済みます。
親から継承したルールを含む構造体の場合は、コンテキスト ツリーでキャッシングが行われます(color プロパティは実際には継承型ですが、Firefox はリセット型のプロパティとして扱い、ルール ツリーにキャッシュします)。
たとえば、パラグラフのフォントに関する次のようなルールを追加しているとします。
p {font-family:Verdana;font size:10px;font-weight:bold}
コンテキスト ツリーで div の子になっているパラグラフ要素は、親と同じフォント構造体を共有できます。そのため、このパラグラフに対して指定されたフォント ルールはありません。
ルール ツリーのない Webkit では、一致した宣言が 4 回走査されます。まず、重要でないが優先度の高いプロパティ(他のプロパティがそのプロパティに依存しているため、最初に適用すべきプロパティ。display など)が適用され、次に優先度の高い重要なルール、通常の優先度で重要でないルール、通常の優先度で重要なルールの順に適用されます。つまり、複数回登場するプロパティは、正しいカスケード順序に従って最終的に解決されます。
まとめると、スタイル オブジェクトを共有することで(全体的に共有する、一部の構造体を共有するなど)、問題の 1 と 3 が解決されます。Firefox のルール ツリーは、プロパティを正しい順序で適用するためにも役立っています。
一致しやすくするためのルールの操作
スタイル ルールにはいくつかのソースがあります。
- CSS ルール。外部のスタイル シートまたは style 要素。
p {color:blue} - インラインの style 属性。
<p style="color:blue" />
- HTML の視覚的属性(関連するスタイル ルールにマッピングされる)
<p bgcolor="blue" />
後者の 2 つは、要素に簡単に一致させることができます。要素自身にスタイル属性があり、その要素をキーとして使って HTML 属性をマッピングできるためです。
先ほど問題 2 で述べたように、CSS ルールのマッチングは複雑になることがあります。問題を解決するため、アクセスしやすくなるようにルールが操作されます。
スタイル シートの解析後、セレクタに従って、複数のハッシュ マップのいずれかにルールが追加されます。id 別、クラス名別、タグ名別のマップや、そのいずれにも該当しない場合の一般的なマップがあります。セレクタが id の場合、ルールは id マップに追加され、クラスの場合はクラス マップに追加されます。
この操作によって、ルールのマッチングが容易になります。マップからその要素に該当するルールを抽出できるため、すべての宣言を調べる必要がなくなります。この最適化によってルールの 95% 以上が除外され、マッチング処理中(4.1)に考慮する必要もなくなります。
たとえば、次のようなスタイル ルールを見てみましょう。
p.error {color:red}
#messageDiv {height:50px}
div {margin:5px}
最初のルールはクラス マップに挿入されます。2 番目のルールは id マップに、3 番目はタグ マップに挿入されます。
次のような HTML の場合、
<p class="error">an error occurred </p> <div id=" messageDiv">this is a message</div>
まず、p 要素のルールを見つけようとします。クラス マップには「error」キーが含まれており、そこで「p.error」のルールが見つかります。div 要素は、id マップ(キーは id)とタグ マップに関連するルールがあります。そのため、あとは、キーを基に抽出されたどちらのルールが実際に一致するかを見つけるだけです。
たとえば、次のような div のルールがある場合、
table div {margin:5px}
キーは右側のセレクタ(div)なので、タグ マップから抽出されますが、マップに含まれる div 要素には table という先祖がないため、一致しないことになります。
Webkit と Firefox のいずれもこの操作を行っています。
正しいカスケード順序でのルールの適用
スタイル オブジェクトには、それぞれの視覚的属性(汎用的な属性を除くすべての css 属性)に対応するプロパティがあります。一致したルールのいずれでもプロパティが定義されていない場合は、親要素のスタイル オブジェクトからプロパティを継承できます。他のプロパティにはデフォルト値があります。
複数の定義がある場合には問題が生じます。そこで、問題を解決するためにカスケード順序が登場します。
スタイル シートのカスケード順序
スタイル プロパティの宣言が複数のスタイル シートにあったり、1 つのスタイル シートで何度も出てきたりする場合があります。その場合はルールを適用する順序が非常に重要になります。これを「カスケード順序」といいます。CSS2 仕様によると、カスケード順序は次のとおりです(低から高の順)。
- ブラウザの宣言
- ユーザーの通常の宣言
- 制作者の通常の宣言
- 制作者の重要な宣言
- ユーザーの重要な宣言
ブラウザの宣言は最も重要性が低く、ユーザーの宣言は「重要(!important)」とマークされている場合にのみ制作者の宣言よりも優先されます。同じ順序の宣言は、特異性に基づいて、次に、指定された順序に基づいて並べ替えられます。HTML の視覚的属性は、一致する CSS の宣言に変換され、優先度の低い制作者のルールとして扱われます。
特異性
セレクタの特異性(specificity)は CSS2 仕様(英語)で次のように定義されています。
- 宣言がセレクタ付きのルールではなく「style」属性にある場合は 1 とカウントし、そうでない場合は 0 とカウントする(= a)
- セレクタ内の ID 属性の数をカウントする(= b)
- セレクタ内の他の属性と擬似クラスの数をカウントする(= c)
- セレクタ内の要素名と擬似要素の数をカウントする(= d)
(大きな基数の数体系で)4 つの数 a-b-c-d を連結すると、特異性が算出されます。
いずれかのカテゴリで最も大きなカウント数を基数として使用する必要があります。
たとえば、a=14 の場合は、16 進数を使用できます。まれなケースですが、a=17 の場合は、17 桁の基数が必要になります。後者の状況は、html body div div p ...(セレクタ内に 17 個のタグがある場合)のようなセレクタで起きることがあります。
次に例を示します。
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
ルールの並べ替え
ルールが一致したら、カスケード ルールに従って並べ替えられます。Webkit では、小さいリストにはバブル ソートを、大きなリストにはマージ ソートを使用しています。ルールの「>」演算子をオーバーライドすることで、並べ替えを実装しています。
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
段階的な処理
Webkit では、すべての上位レベルのスタイル シート(@import を含む)が読み込まれたかどうかをマークするフラグを使用しています。関連付けの際にスタイルが完全に読み込まれていない場合は(プレースホルダを使ってドキュメント内にマークされている場合)、スタイル シートが読み込まれるとプレースホルダのスタイルが再計算されます。
レイアウト
レンダラーを作成してツリーに追加したとき、レンダラーには位置やサイズがありません。これらの値を計算することを「レイアウト」または「リフロー」といいます。
HTML ではフローに基づいたレイアウト モデルを使用しています。つまり、ほとんどの時間、1 つのパス上で配置の計算が可能です。通常、フロー内で後の方の要素が最初の方の要素の配置に影響を与えることはないため、ドキュメントの左から右へ、上から下へとレイアウトを進めることができます。ただし、例外もあります。たとえば、HTML テーブルでは複数のパスが必要になることがあります(3.5)。
座標系はルートのフレームに対して相対的です。トップと左の座標が使用されます。
レイアウトは再帰的な処理です。HTML ドキュメントの <html> 要素に対応するルートのレンダラーから始まります。レイアウトはフレーム階層の一部またはすべてを再帰的に進みながら、各レンダラーで必要な幾何学的情報を計算していきます。
ルートのレンダラーの位置は「0,0」で、寸法はビューポート(ブラウザ ウィンドウの表示可能な部分)です。
すべてのレンダラーには「layout」または「reflow」メソッドがあり、各レンダラーはレイアウトが必要な子の layout メソッドを呼び出します。
ダーティ ビット システム
小さな変更があるたびに完全なレイアウト処理を行わなくても済むように、ブラウザでは「ダーティ ビット」システムを使用しています。変更または追加されたレンダラーは自身とその子を「ダーティ」としてマークし、レイアウトが必要なことを表します。
「ダーティ(dirty)」と「子がダーティ(children are dirty)」の 2 つのフラグがあります。「子がダーティ」とは、レンダラー自体はそのままでよいが、レイアウトが必要な子が少なくとも 1 つあるという意味です。
グローバル レイアウトとインクリメンタル レイアウト
レンダー ツリー全体のレイアウトを開始することができます。これを「グローバル」レイアウトといいます。グローバル レイアウトは次のような場合に行われます。
- すべてのレンダラーに影響するグローバルなスタイルの変更(フォント サイズの変更など)があった場合。
- 画面がサイズ変更された場合。
ダーティなレンダラーのみをレイアウトする「インクリメンタル」レイアウトもあります(その場合は、問題が発生して特別なレイアウトが必要になることもあります)。
インクリメンタル レイアウトはレンダラーがダーティな場合に(非同期的に)開始されます。たとえば、特別なコンテンツがネットワークから届いて DOM ツリーに追加された後で、レンダー ツリーに新しいレンダラーが追加された場合などです。
非同期と同期のレイアウト
インクリメンタル レイアウトは非同期的に行われます。Firefox ではインクリメンタル レイアウトの「reflow コマンド」をキューに入れておき、スケジューラがこれらのコマンドの一括実行を開始します。Webkit にもインクリメンタル レイアウトを実行するタイマーがあります。ツリーが走査され、「ダーティ」なレンダラーがレイアウトされます。
スタイル情報(offsetHeight など)を要求するスクリプトでは、インクリメンタル レイアウトを同期的に開始できます。
グローバル レイアウトは通常は同期的に行われます。
スクロール位置など一部の属性が変更されたために、初期レイアウトの後でコールバックとしてレイアウトが開始される場合もあります。
最適化
「サイズ変更」やレンダラーの位置の変更などによりレイアウトが開始された場合、レンダー サイズは再計算されずに、キャッシュから取得されます。
サブツリーのみが変更された場合には、レイアウトがルートから開始されない場合もあります。たとえば、テキスト フィールドへのテキストの挿入など、変更が局所的で周囲に影響を与えない場合です(それ以外の場合は、キーストロークがあるたびにルートから始まるレイアウトが開始されます)。
レイアウト処理
通常、レイアウトには次のようなパターンがあります。
- 親レンダラーが自身の幅を決定します。
- 親が子を確認して、
- 子レンダラーを配置します(x と y を設定します)。
- (子がダーティな場合や、グローバル レイアウトなどで)必要な場合は子の layout メソッドを呼び出します。これにより、子の高さを計算します。
- 親は子の高さの累積、マージンの高さ、パディングを使用して、自身の高さを設定します。この高さは親レンダラーのさらに親によって使用されます。
- ダーティ ビットを false に設定します。
Firefox では、layout メソッド(名称は「reflow」)のパラメータとして「状態」オブジェクト(nsHTMLReflowState)を使用しています。状態オブジェクトには親の幅などが格納されます。
Firefox の layout の出力は「指標」オブジェクト(nsHTMLReflowMetrics)です。このオブジェクトには、計算されたレンダラーの高さが格納されます。
幅の計算
レンダラーの幅は、コンテナ ブロックの幅、レンダラーのスタイルの「width」プロパティ、マージン、ボーダーを使用して計算されます。
たとえば、次のような div の幅は、
<div style="width:30%"/>
Webkit によって次のように計算されます(RenderBox クラスの calcWidth メソッド)。
- コンテナの幅は、コンテナの availableWidth と 0 のうち大きい方の値です。この場合の availableWidth は次のように計算される contentWidth です。
clientWidth() - paddingLeft() - paddingRight()
clientWidth と clientHeight は、ボーダーとスクロールバー以外のオブジェクトの内寸を表します。 - 要素の幅は「width」スタイル属性です。コンテナの幅に対する割合を計算して、絶対値として算出されます。
- 水平ボーダーとパディングが追加されます。
これまでは、「望ましい幅」の計算でした。ここで、最小幅と最大幅を計算します。
望ましい幅が最大幅よりも大きい場合は、最大幅が使用されます。最小幅(それ以上分割できない最小単位)より小さい場合は、最小幅が使用されます。
レイアウトの必要があるが幅が変わらない場合に備えて、これらの値はキャッシュされます。
改行
レンダラーがレイアウト中に改行の必要があると判断した場合は、レイアウトを中断して、改行の必要があることを親に伝えます。親は別のレンダラーを作成して、そのレンダラーの layout メソッドを呼び出します。
描画
描画段階では、レンダー ツリーを走査し、レンダラーの「paint」メソッドを呼び出して、そのコンテンツを画面上に表示します。描画では UI インフラストラクチャ コンポーネントが使用されます。
グローバルとインクリメンタル
レイアウトと同様に、描画にもグローバル(ツリー全体の描画)とインクリメンタルがあります。インクリメンタルな描画では、一部のレンダラーがツリー全体に影響を与えない方法で変更されます。変更されたレンダラーは画面上で自身の矩形を無効にします。それにより、OS はその矩形を「ダーティな領域」と見なし、「描画」イベントを生成します。OS はこの処理を合理的に行い、複数の領域を 1 つにまとめます。Chrome では、レンダラーがメイン プロセスとは別のプロセスにあるため、これより複雑になります。Chrome は OS の動作をある程度までシミュレートします。プレゼンテーションがこれらのイベントをリッスンし、メッセージをレンダーのルートに委譲します。該当するレンダラーに到達するまでツリーが走査されて、レンダラー自身(と通常はその子)が再描画されます。
描画の順序
CSS2(英語)では、描画処理の順序を定義しています。これは実際には、
スタッキング コンテキストに要素がスタックされる順序です。スタックは後ろから前に描画されるため、この順序が描画に影響を与えます。ブロック レンダラーのスタッキング順序は次のとおりです。
- 背景色
- 背景画像
- ボーダー
- 子
- アウトライン
Firefox の表示リスト
Firefox ではレンダー ツリーを調べて、描画される矩形の表示リストを作成します。このリストには、矩形に関連するレンダラーが正しい描画順序(レンダラーの背景色、次にボーダーなど)で含まれています。そのため、再描画のときはツリーを複数回ではなく 1 回走査するだけで済みます(すべての背景色、すべての画像、すべてのボーダーの順に描画します)。
Firefox では、隠れる要素(他の不透明な要素の下に完全に隠れる要素など)を追加しないことによって、プロセスを最適化しています。
Webkit の矩形ストレージ
再描画の前に、Webkit では古い矩形をビットマップとして保存します。その後で、新しい矩形と古い矩形の差分のみを描画します。
動的な変更
ブラウザでは、変更に対応して最小限の操作を実行しようとします。そのため、要素の色が変更された場合は、その要素の再描画のみを行います。要素の位置が変更された場合は、要素とその子や兄弟のレイアウトと再描画を行います。DOM ノードを追加すると、ノードのレイアウトと再描画が行われます。「html」要素のフォント サイズを増やすなど、大きな変更を加えた場合は、キャッシュが無効になり、ツリー全体の再レイアウトと再描画が行われます。
レンダリング エンジンのスレッド
レンダリング エンジンはシングル スレッドです。ネットワーク処理以外のすべての処理がシングル スレッドで行われます。Firefox と Safari では、これはブラウザのメイン スレッドです。Chrome では、タブ プロセスのメイン スレッドです。
ネットワーク処理は複数の並列スレッドで実行できます。並列接続の数は制限されています(通常は 2~6 接続。たとえば、Firefox 3 では 6 接続を使用します)。
イベント ループ
ブラウザのメイン スレッドはイベント ループです。プロセスを維持し続ける無限ループです。イベント(レイアウト イベントや描画イベント)を待機して処理します。Firefox のメインのイベント ループのコードは次のとおりです。
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 の視覚的モデル
キャンバス
CSS2 仕様(英語)によると、「キャンバス」とは「書式設定された構造をレンダリングするスペース」のことです。つまり、ブラウザがコンテンツを描画する場所です。キャンバスの大きさは無限ですが、ブラウザではビューポートの寸法に基づいて最初の幅を選択します。
www.w3.org/TR/CSS2/zindex.html(英語)によると、キャンバスは別のキャンバスに含まれている場合は透明になり、そうでない場合はブラウザで定義された色になります。
CSS のボックス モデル
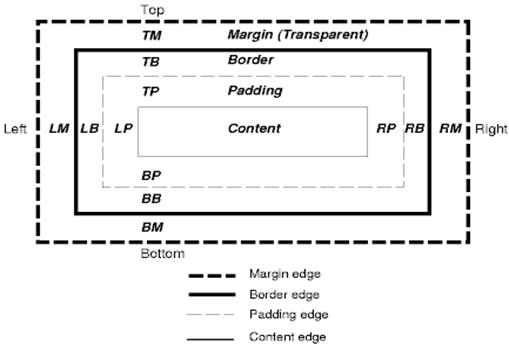
CSS のボックス モデル(リンク先は英語)では、ドキュメント ツリーの要素に対して生成され、視覚的な書式設定モデルに従ってレイアウトされる矩形のボックスについて説明しています。
各ボックスには、コンテンツ領域(テキスト、画像など)と、周囲のパディング、ボーダー、マージンの領域(省略可能)があります。
各ノードではこのようなボックスを 0~n 個生成します。
すべての要素には、生成されるボックスのタイプを指定した「display」プロパティがあります。次に例を示します。
block - generates a block box. inline - generates one or more inline boxes. none - no box is generated.
デフォルトは「inline」ですが、ブラウザのスタイル シートでは他のデフォルトが設定されます。たとえば、「div」要素のデフォルトの「display」は「block」です。
デフォルトのスタイル シートの例については、
www.w3.org/TR/CSS2/sample.htmlをご覧ください。
配置方法
次の 3 つの方法があります。
- 通常 - オブジェクトはドキュメント内の場所に従って配置されます。つまり、レンダー ツリー内の場所は DOM ツリー内の場所と同様になり、ボックスの種類や寸法に従ってレイアウトされます。
- フロート - オブジェクトは最初に通常のフローのようにレイアウトされてから、左右のできるだけ遠くに移動されます。
- 絶対 - オブジェクトはレンダー ツリー内で DOM ツリーとは異なる場所に配置されます。
配置方法は「position」プロパティと「float」属性で設定します。
- 「static」と「relative」の場合は「通常」のフローになります。
- 「absolute」と「fixed」の場合は「絶対」の配置になります。
「static」の配置方法の場合、位置は定義されず、デフォルトの配置方法が使用されます。それ以外の方法では、制作者が位置を指定します(top、bottom、left、right)。
ボックスのレイアウト方法は次の要因で決まります。
- ボックスの種類
- ボックスの寸法
- 配置方法
- 外部の情報(画像サイズや画面のサイズなど)
ボックスの種類
ブロック ボックス: ブラウザ ウィンドウ上に独自の矩形があり、ブロックを形成します。
インライン ボックス: 独自のブロックは持たず、包含ブロックの内側に置かれます。

ブロックは垂直に順々に配列されます。インラインは水平に配列されます。

インライン ボックスはラインまたは「ライン ボックス」の内側に置かれます。ラインの高さは 1 番高いボックスと同じになりますが、ボックスが「基準線」に沿って並んでいる場合、つまり、ボックスの下部が他のボックスの底辺以外の位置と揃っている場合は、それより高くなることもあります。コンテナの幅が十分でない場合、インラインは複数のラインに置かれます。この状況は、通常はパラグラフで発生します。

配置
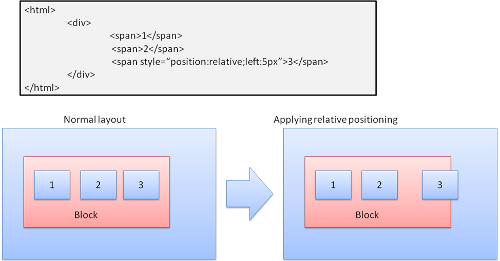
相対
相対の配置 - 通常どおりに配置してから、必要な差分だけ移動します。
フロート
フロート ボックスはラインの左または右に移動されます。他のボックスが回り込む点が特徴的です。次のような HTML は、
<p> <img style="float:right" src="images/image.gif" width="100" height="100"> Lorem ipsum dolor sit amet, consectetuer... </p>
次のような配置になります。

絶対と固定
レイアウトは通常のフローに関係なく厳密に定義されます。この要素は通常のフローには関与しません。寸法はコンテナに対して相対的になります。固定の場合、コンテナはビューポートです。

注 - 固定のボックスはドキュメントがスクロールされても移動しません。
レイヤの表現
CSS の z-index プロパティで指定します。このプロパティは、ボックスの第 3 の寸法である z 軸上の位置を表します。
ボックスはスタック(スタッキング コンテキスト)に分けられます。各スタックでは、最初に後ろの要素が描画され、その上に前方の(ユーザーに近い方の)要素が描画されます。オーバーラップの場合は、前方の要素が隠されます。
スタックの順序は z-index プロパティに従います。z-index プロパティを持つ複数のボックスがローカル スタックを形成します。ビューポートは外側にスタックがあります。
次の例の場合、
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
次のような結果になります。

赤い div はマークアップでは緑の div より前にあり、通常のフローより前に描画されますが、z-index の値が大きいため、スタック内で前方に表示されて、下のボックスに囲まれることになります。