2011.8
 やあみんな、ビリーだよ。
やあみんな、ビリーだよ。
今回は、前回に続いてヒープとスタックについて説明しよう。
ヒープもスタックも、プログラム中で一時的に使用されるメモリ領域、
ということは前回紹介したけど、
まとめると、
この2つにはこんな違いがあるんだ。
- コンパイラやOSが自動的に割り当て、解放を行う。
- Auto変数はスタックに確保される。(「七の巻:スタックってなあに?(3)」を参照)
- サイズは、プログラムをコンパイル、リンクする時点で決まっている。
- アプリケーションが、メモリが必要になった時に確保し、不要になったら解放するという処理を自分自身で行う必要がある。
- サイズは、メモリを確保する時に動的に指定することができる。
それじゃあ、これらをどうやって使い分ければいいのだろう?
アプリケーションを組む時に、スタックかヒープかを選択できる場面としては「変数の配置」があるんだ。
まずはこれを例に見ていこう。
スタックは、OS やコンパイラが自動的に領域を割り当てるから、プログラムを組むのが楽というのがメリットになるよね。
その一方で、使用できるサイズは決まっているので、使いすぎるとスタックがオーバーフローし、
他の領域を書きつぶしてしまうという問題もあるんだ。
(「七の巻:スタックってなあに?(4)」を参照)
逆に、不必要に大きなスタックを割り当てると、使われない領域が無駄に存在することになってしまって、
組込みではよろしくないよね。
つまり、スタックは比較的サイズが小さくて、特定の関数内でしか使わない変数に向いている。
そうすれば、スタックのサイズを小さく設定することができるよね。
例えば、下記の i や data のような変数がこれにあたる。

これに対してヒープは、使用するサイズとタイミングを、アプリケーションで決められるというのがメリットになる。
組込み機器ではメモリの容量が限られており、
使っていないメモリは解放して他の処理と共用で使うよう工夫するべきなので、比較的サイズか大きいもの、
サイズが可変のものがヒープに適しているということだよね。
例えば、ファイルを読み出す際のバッファを割り当てる場合で、

といった具合だ。
ファイルのサイズは毎回同じとは限らないので、ファイルサイズ分だけメモリをヒープに確保すれば、
無駄にメモリを消費することはないよね。
これをスタックで実現しようとすれば、ファイルサイズが最も大きくなる場合を想定しておかなければならない。
例えば 1000〜10000 バイトのファイルを扱うとすれば
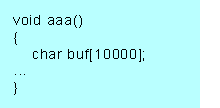
というように、最大に使用する想定でスタック変数を確保する必要があるね。
ファイルが 1000 バイトの場合は、9000 バイトは使用されない領域となってしまう。
ただ、このような大きなサイズの配列は、関数内ではなく静的領域として確保する場合もあるよ。
グローバル変数として、
![]()
とするような場合だ。
この場合も、やっぱり最大に使用する想定で、あらかじめ割り当てておく必要があることには変わりはないんだけどね。
ただし、ヒープメモリの確保、解放(malloc(), free())を頻繁に行うことはやめておいたほうがいいかもしれないよ。
フラグメンテーション(メモリが虫食い状態になる)を起こす原因となるからなんだ。
フラグメンテーションについては、次回の講義で紹介してみようと思ってるので、お楽しみに。
OSを使う場合は、タスクごとのスタック割り当てや、ヒープメモリの管理はOSでやってくれるんだけど、
OSを使用しないシステムの場合はどうなっているんだろう?
 OSを使わない場合、スタックはシステム全体で一箇所を使用することになる。
OSを使わない場合、スタックはシステム全体で一箇所を使用することになる。
この場合も、スタック変数の割り当てなどはコンパイラやリンカがやってくれるので、
プログラマーは特別な意識をする必要は無いんだけど、
スタックのオーバーフローは注意してなくっちゃダメだよね。
ヒープメモリについては、mallocなどのメモリ割り当て関数が、
開発環境(コンパイラ)に付属する標準ライブラリでサポートされている場合もあるんだけど、
ない場合は自分で作る必要がある。
また次回説明予定の「フラグメンテーション」を回避するために、
あえてOSや標準ライブラリで用意されているヒープメモリ管理機能を使用しないで、
自前でメモリ管理を行うこともあるんだよ。
限られたメモリで、頻繁にヒープメモリの確保と開放を行う必要があるシステムでは、このようなやり方になるし、
東電ユークエストのミドルウェアでもこの技術が使われているんだ。
標準ライブラリでサポートされているメモリ管理は、例えばこんなふうになっている。
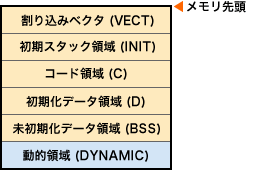
左記のように、「動的領域」というエリア(セクション)を
割り当てておくんだ。
普通はこれはリンカで指定するようになっていて、
開始アドレスやサイズをあらかじめ決めておく。
スタック、ヒープ領域は、この「動的領域」を使用することになるね。
プログラマは、「動的領域」のアドレスとサイズを決め、
スタックやヒープの配分も決めておかなければならないんだ。
今まで見てきたように、スタックは少なくすればスタックオーバーフローの危険性があるし、
大きくすれば無駄に使われないメモリが存在することになるよね。
スタックサイズの調節は、限られたメモリを最大限有効に使うための、プログラマーの腕の見せ所だ。
スタックサイズを決めるには、
- スタック変数のサイズや関数呼び出しの回数から計算する。
- スタックを多めに取っておいて、実際にプログラムを動作させて使用実績を測定する。
- 開発環境で用意されているスタックサイズ見積ツール活用する。
などの方法があるんだ。
今回は、前回やったスタックとヒープの特徴を踏まえて、どのように設定し、どのように使うかを話してみたよ。
スタックとヒープのもつ意味と違いが分かっていれば、それほど難しい内容じゃなかったよね。
さっきも言ったけど、次回はメモリを使う場合に注意しなくてはいけない「フラグメンテーション」について話していくよ。
拾六の巻: DMA対応と言われたら![]() 拾八の巻:フラグメンテーション
拾八の巻:フラグメンテーション
![]()
![]()